Lessons in Human Psychology, Or How I taught Machines Kung Fu
Table of Contents
I Know Learnt Kung Fu#

Imagine yourself in a Hollywood Thriller. You wake up in a dark room without any memory of how you got there or what are you doing there. All you know is you need to get out somehow but don’t have any instructions on how to do so. You can’t really see anything, but someone keeps shouting random words. Every time you do something, you either feel a sharp bout of pain or a bit of exhilaration that becomes your sole guide. Gradually, you figure out the connection between those random words and your actions and you start making your way through and soon see the light at the end of the tunnel.
This, in a nutshell, is Reinforcement Learning. What I thought would be a short project teaching an AI how to play a game, became a master class in what motivates people to do something.
Finally, the agent learnt a simple trick to beat the game and optimize for the shortest path to success, even though it had learnt to fight and defend pretty well. Just run
In the 1980s and 90s, we spent hours and hours role playing as Kung Fu Masters in the classic NES game of the same name, also known as Spartan-X in Japan. Trying to go faster, clearing the stages in the least amount of time, with the minimal but precisely delivered punches and kicks was the aim. Last week, I took it upon myself to teach a machine to be as good as myself at it (a tall order, I know). This, is a story of how I built an agent in Rust, and trained it to be Jackie Chan. Buckle up, it’s going to be a bit long!
(PS: If you can’t wait and just want to see it in action, there’s a video at the bottom of the post. See it, but come back to read. It’s going to be interesting, I promise. Full code is available and this post will teach you enough to be able to change things and train your own agent in your own style!)

Reinforcement Learning: State, Action, Reward, Done#
These are the key building blocks of any RL problem:
- State: The current situation of the environment. In our case, this is the current state of the game, which includes the positions of the player, enemies, and any other relevant information.
- Action: The possible moves the agent can make. In our case, this includes moving left, moving right, jumping, punching, kicking, etc.
- Reward: The feedback the agent receives after taking an action. In our case, this could be points scored for defeating an enemy, losing a life, or completing a level and other things.
I’ll talk a bit about each of these in the context of our game, how I implemented them, and how the challenges faced evolved the architecture of the agent and the training process.
The agent held up a mirror. How many times do we optimize for the wrong metrics? Chase points instead of purpose? Take the path of least resistance when the scenic route teaches more?
State: Let there be light! Giving eyes to the machine#
Google’s Deepmind released their seminal DQN (Deep Q Network) paper that introduced deep reinforcement learning (RL) to play Atari games was released in 2013, more than a decade ago from now. One of the games they played with their network at that time was Kung Fu Master for Atari. They gave literal eyes to the network, giving it a feed of raw pixels from the game’s frames being rendered combining a CNN with a Q-learning algorithm. This served as the State for the network.
I chose a slightly different architecture, a Dueling Double DQN, that improves upon the original paper but more importantly I chose to do it The Cypher Way. Cypher doesn’t need to see an image. The code IS his image.
(PS: The code of this project is here if you want to follow along while reading this post: https://github.com/shantanugoel/kungfu_nes_rl_rust)

Emulators, our Lord and Savior#
All these classics would’ve been lost to history, were it not for the kind and awesome folks who make emulators for these older consoles. These emulators, besides giving us the joy to play the games, also expose a lot of debug tooling that we can use to know and understand the Ins and Outs of the games. FCEUX is a pretty popular emulator but it hasn’t made a release in a few years and needs Rosetta to be installed on macOS M-series machines. So I went with Mesen 2, which turned out to be an equally (if not more) competent emulator for our purpose. Not only it is pretty full featured to support all the gaming features, but has a good amount of debug tooling as well, e.g. a nice Memory Viewer which is the most essential.
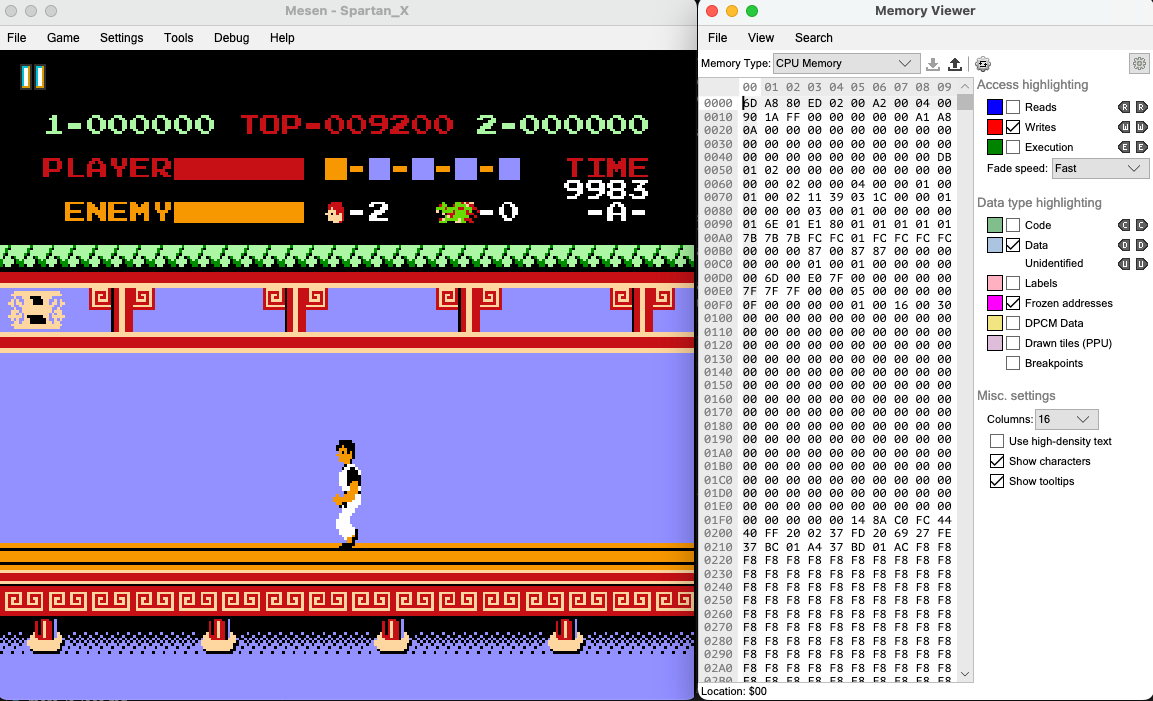
So, I fired up Mesen, loaded the ROM for the game and started poking around to see how I can get the state of the game. My first thought was “Surely, someone must have done this earlier for this game, given how popular it was and we should have a lot of information available about the code and where the game state is stored in the memory”.
I was WRONG. There’s surprisingly little information available about the inner workings of the game, and I had to do a lot of reverse engineering to figure out what is what. I painstakingly stepped through frame by frame, looking at the bits that changed everywhere, correlating them with what I was seeing on the screen and trying to figure out what they represent. At various points I wrote lua scripts to dump the memory into files per frame and coordinated with a python script to diff the contents in real time per frame to narrow down the choices, but a lot of the time I just eyeballed things. This took easily the most amount of time in all of my work, both in determining what actual features should I put into the state that would make sense and how to figure out where they are in the memory.
80s: A time of total chad programmers#
The things that made it more difficult for me was that the game uses a lot of clever tricks given how low on resources the consoles used to be those days. Few such things I discovered:
- When I was trying to get the positions of the player and the enemies, I kept faltering even after I discovered the memory locations. Debugging this through the Tilemap viewer and the sprite viewer, I found that when the player moves, even though his coordinates are changing, he isn’t really moving. The game keeps the player literally fixed in the center of the screen and scrolls the background instead in a window of fixed width in the opposite direction, and efficiently brings in the enemies as sprites. The window keeps wrapping around giving the illusion of continuous progress. You can see below how little is actually changing on the screen at any given time.
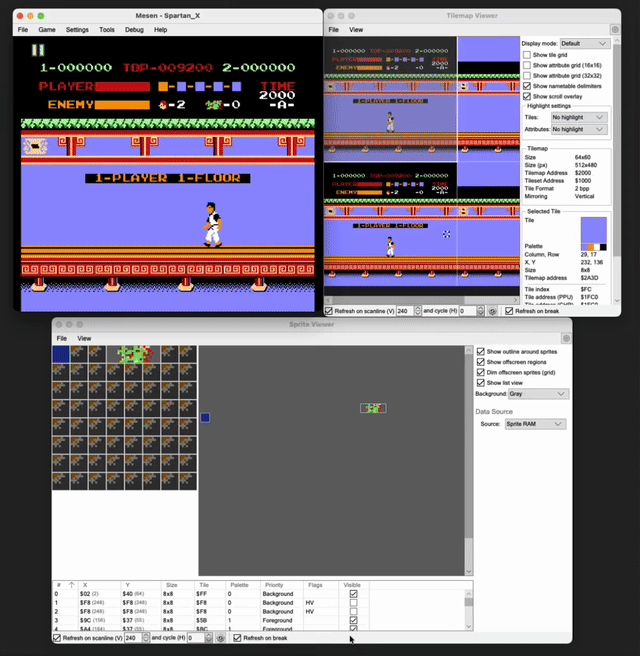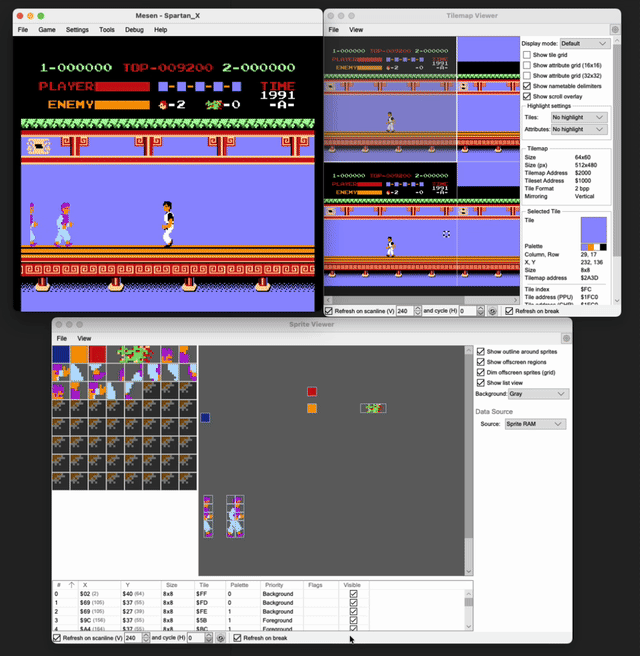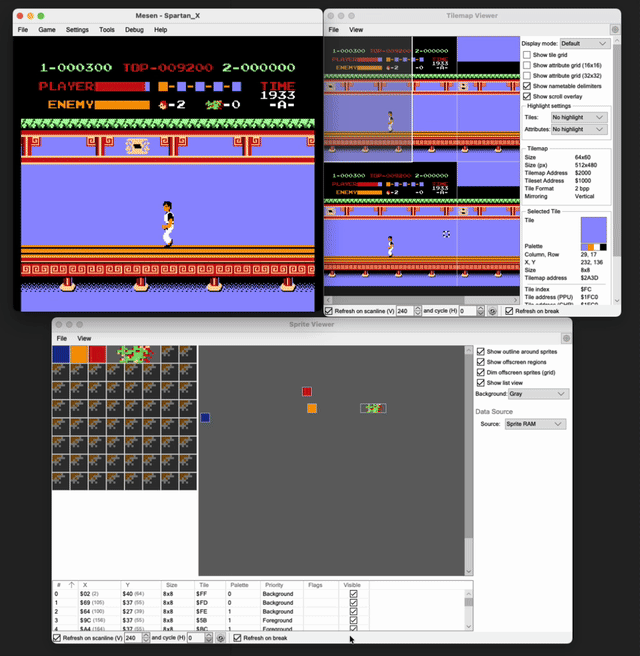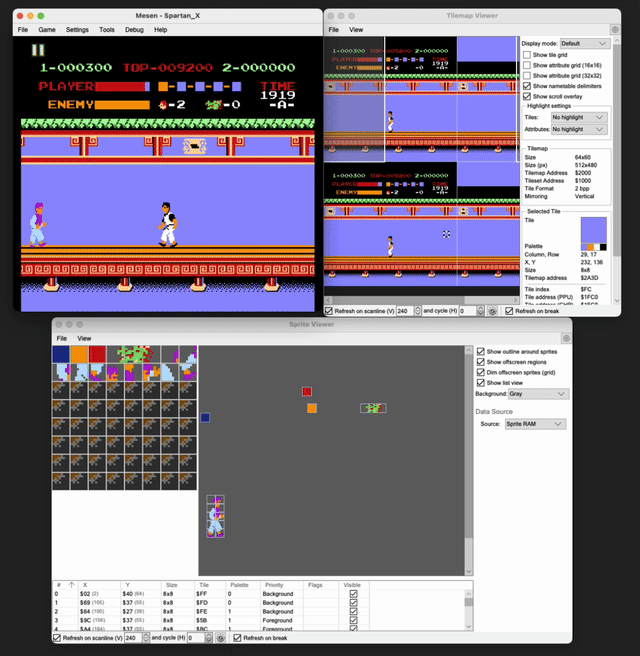
The game had also dedicated only 1 byte each for the x and y position of the player and it kept wrapping around from 255 to 0 as I moved leftwards. And there was a
pagenumber change that happened whenever the player’s x coordinate hit 0x7F.The game also had only 4 slots to process any enemies on the screen (except the boss which had its own slot). And those slots kept getting recycled and reused as the enemies kept dying or appearing. This was even across the different types of enemies.
The throwables on the screen, like the knives from the knife throwers, had their own separate slots.
Different things and types of enemies had different characteristics of attack patterns and velocity of movement, everything cycling through a discrete value somewhere in RAM
All of these, and many more such things, meant that I had to spend a lot of time to figure out how they interacted with the player, e.g. where they were relatively placed at any given point of time and how soon they will reach, were they about to make a specific type of attack and going through that cycle (e.g. a knife thrower pulling the hand back, and then either raising it or lowering it before it throws a knife meant the cycle branched in different directions)
A lot of the things were BCD encoded across several bytes (E.g. the timer, and the score) and others were pure hex numbers.
A lot of these states were continuous but with skips/glitches/wraparounds (like the movement x/y) and others were discrete ones which I had to decide whether to encode them as one-hot or just scale them as a scalar.
But we find a way#
Everything was not bad though. A couple of advantages I had were:
- Given the low amount of working RAM the game had at its disposal (just 2 KB), it often brought a lot of the parameters in to the first page (0x00 to 0xFF - 255 bytes) from other areas of RAM and ROM so it could access them faster.
- Mesen has a very nice lua scripting interface, so I wrote a
God Modescript which allowed me to explore the game easily. I made the script so that it gave me infinite health, killed any enemy as soon as it appeared on the screen, and kept overwriting the timer to always have 9999 seconds left so it didn’t time out.
I started out on Day 1, doing a lot of research, and building around 49 parameters which I thought was pretty extensive. Little did I know that I will have to keep figuring out more and more as I tried and failed. Few examples of things I added as I went along, and there were many more besides figuring out their limits and their nature to determine their encoding etc:
The knives had their owne sequence for their life cycle
Figuring out which direction the player and the enemies are facing. This was crucial for it to learn whether to hit behind or in front
I had to add the player pose and state to also see what the player was doing when something happened. Just x/y wasn’t enough because a different pose/state would mean its hitbox covering different tiles
Some enemies died with a single hit, while others had multi-hit
energylocations to be figured out, and then the Boss had his own full health bar to be tracked.Figuring out how to see if the boss or a particular type of enemy is actually active on the screen or not, because the game didn’t clear off dead/not-yet-appeared enemies’ states from the RAM to save cycles
The enemy velocity was nowhere to be found, most likely hardcoded into the ROM. So I had to deduce it by doing a frame diff.
A special
Shrugstate where the grabbers grab the agent, making it unable to move. Without this, suddenly the output of action is gone!
Each of these fixes, as I figured them out, felt like cleaning a fogged lens. Suddenly the agent could make sense of the things because The Matrix was all around him.
Finally I settled on a 99-parameter state representation made out of the RAM map I pieced together as below:
Link: https://github.com/shantanugoel/kungfu_nes_rl_rust/blob/main/RAM_MAP.md
# RAM Map - Kung Fu (NES)
This document tracks the memory addresses used for state extraction in the `kungfu_rl_rs` project.
## Confirmed Addresses
| Address | Name | Size | Description | Potential Values / Meanings |
| :--- | :--- | :--- | :--- | :--- |
| `0x005C` | `PLAYER_LIVES` | 1 | Remaining lives. | Typically 0-5 (3 at start). |
| `0x00D4` | `PLAYER_X` | 1 | Player horizontal position. | 0-255 (screen-space). |
| `0x00D3` | `BOSS_X` | 1 | Boss horizontal position. | 0-255 (screen-space). |
| `0x00B6` | `PLAYER_Y` | 1 | Player vertical position. | 0-255 (screen-space). |
| `0x00B5` | `BOSS_Y` | 1 | Boss vertical position. | 0-255 (screen-space). |
| `0x04A6` | `PLAYER_HP` | 1 | Player health points (see Technical Notes). | 0-48 expected, `0xFF` sentinel during death. |
| `0x04A5` | `BOSS_HP` | 1 | Same as Player at least on floor 1. | 0-48, `0xFF` sentinel during death. |
| `0x036E` | `PLAYER_POSE` | 1 | Player pose/animation index. | Changes with actions and movement. Also in 0x0069|
| `0x036F` | `PLAYER_STATE` | 1 | Player direction and attack state (see Notes). | Low nibble: direction/stance; high nibble: attack type. |
| `0x0065` | `PAGE` | 1 | Screen/page number for horizontal scroll. | Increments/decrements on screen transitions. |
| `0x00CE - 0x00D1` | `ENEMY_X` | 4 | X positions for enemy slots 0 through 3. | 0-255 (screen-space). |
| `0x0087 - 0x008A` | `ENEMY_TYPE` | 4 | Enemy type identifiers for slots 0 through 3. | 0-7 observed (enemy class id). |
| `0x00B0 - 0x00B3` | `ENEMY_Y` | 4 | Y positions for enemy slots 0 through 3. | 0-255 (screen-space). |
| `0x00C0 - 0x00C3` | `ENEMY_FACING` | 4 | Facing direction for enemy slots 0 through 3. | 0/Non-zero (L/R). |
| `0x00C5` | `BOSS_FACING` | 1 | Facing direction for boss. | 0/Non-zero (L/R). |
| `0x00DF - 0x00E2` | `ENEMY_POSE` | 4 | Animation state for enemy slots 0 through 3. | Nonzero indicates active; `0x7F` seen as inactive. |
| `0x00B7 - 0x00BA` | `ENEMY_ATTACK` | 4 | Attack state for enemy slots 0 through 6. | Nonzero indicates active; `0x7F` seen as inactive. |
| `0x00BC` | `BOSS_ATTACK` | 1 | Attack state for Boss. | Cycles 0 through 9. |
| `0x04A0 - 0x04A3` | `ENEMY_ENERGY` | 4 | Enemy energy per slot 0 through 3. | See Enemy Energy Behavior. |
| `0x03D4 - 0x03D7` | `KNIFE_X` | 4 | Knife projectile X positions for slots 0 through 3. | 0-255; 0 or `0xF9` when off-screen. |
| `0x03D0 - 0x03D3` | `KNIFE_Y` | 4 | Knife projectile Y positions for slots 0 through 3. | 0-255 (screen-space). |
| `0x03EC - 0x03EF` | `KNIFE_STATE` | 4 | Knife active + facing for slots 0 through 3. | `0x00` inactive, `0x11` facing right, `0x01` facing left. |
| `0x03F0 - 0x03F3` | `KNIFE_THROW_SEQ` | 4 | Knife throw sequence counter for slots 0 through 3. | Increments on throw; cycles 0-3. |
| `0x03B1` | `KILL_COUNTER` | 1 | Total number of enemies defeated in current run. | Monotonic counter, wraps at 255. |
| `0x0531 - 0x0536` | `SCORE_DIGITS` | 6 | BCD-encoded score digits. | Each byte is a single digit 0-9 (low nibble). |
| `0x0501 - 0x0506` | `TOP_SCORE_DIGITS` | 6 | BCD-encoded score digits. | Each byte is a single digit 0-9 (low nibble). |
| `0x0390 - 0x0393` | `TIMER_DIGITS` | 4 | BCD-encoded timer digits. | Four-digit timer (e.g., 1079). |
| `0x005F` | `FLOOR` | 1 | Tracks the current stage/floor level. | Small integer that increments on floor transition (0-5 or 1-6). |
| `0x00E4` | `BOSS_ACTIVE` | 1 | Boss is active or not. Use other boss signals based on this. | 0 when not active, 1 when active, 0x7F when died |
| `0x373` | `SHRUG_COUNTER` | 1 | Enemies (grabbers) hugging the player | Count of how many enemies are hugging the players right now, so can be between 0 to 4 |
## Unconfirmed / To Verify
| Address | Name | Status | Notes | Potential Values / Meanings |
| :--- | :--- | :--- | :--- | :--- |
| `0x0050` | `PLAYER_STATE` | To Verify | Legacy placeholder, superseded by `0x036F`. | Remove from code once unused. |
## Technical Notes
### Player HP Behavior
The `PLAYER_HP` address (`0x04A6`) occasionally reads `0xFF` during the death sequence or transition.
- Treatment: When reading this value for reinforcement learning observations, treat it as `0` (dead) or clamp to the expected maximum range to avoid reward spikes.
- Observed range: 0-48 for this ROM.
### Score Mapping
The address `0x0534` specifically maps to one of the decimal places in the HUD score. Any previous documentation suggesting this is `BOSS_HP` should be disregarded.
### Player State Encoding (`0x036F`)
Low nibble:
- 0: left standing
- 1: right standing
- 2: left facing down
- 3: right facing down
- 4: left facing jump
- 5: right facing jump
High nibble:
- 0: neutral
- 1: kicking
- 2: punching
- (possible 1/2 combo for attacking)
### Knife/Projectile Behavior
Use `KNIFE_STATE` to determine active projectiles; treat `KNIFE_X` and `KNIFE_Y` as valid only when the corresponding state is nonzero.
### Enemy Energy Behavior
- 1-hit enemies: `ENEMY_ENERGY` reads `0x00` while active; on death it becomes `0xFF` momentarily.
- 2-hit enemies: `ENEMY_ENERGY` starts at `0x01`; after the first hit it becomes `0x00`; on the killing hit it becomes `0xFF` momentarily.
Action: With great power, comes great responsibility#
On the surface, the game has 6 controls. Left, Right, Up, Down, Kick, Punch. The first two naive ways I built up my action space failed spectacularly:
Just have the above 6 basic controls as available actions each frame. This failed because often you want to do something like jump AND kick. Or kick someone behind you, or crouch and punch, etc. So this limited action space wasn’t enough for the agent to progress.
Next I built up a huge action space of all possible combos. This failed as well because the state became too sparse and a lot to choose from. Maybe the agent would’ve ultimately learnt from it but it might taken several times more training. who knows!
Sometimes, the best action is no action. yes, I didn’t have any
NOOPaka do nothing action. This was quite pivotal moment that was useful when the player should actually just wait for the enemy to make a moveFinally I created an action space of these 13 combos, the thinking being that the player can just not do anything, move in a direction without attacking, or attack with a direction (Just kicking is still same as kicking in the same direction as you are facing)
Link: https://github.com/shantanugoel/kungfu_nes_rl_rust/blob/main/src/env.rs
pub enum Action {
Noop = 0,
Right = 1,
Left = 2,
Crouch = 3,
Jump = 4,
RightPunch = 5,
RightKick = 6,
LeftPunch = 7,
LeftKick = 8,
CrouchPunch = 9,
CrouchKick = 10,
JumpPunch = 11,
JumpKick = 12,
}
Reward: Reward shaping is behavioral psychology in code#
Goodhart’s Law: When a measure becomes a target, it ceases to be a good measure.
This was the second most time consuming and head scratching aspect in the whole project. It was as if I wasn’t writing code, but was trying to be a Parent.
After doing this over the last week, I have new found respect for game developers who find balance in much much more complex games of day! Because the agent behaves just like a human on capitalising on the rewards it is presented with!
The situation needs a multi-fold analysis:
- What to reward for
- Which ones should be positive or negative
- How much to reward for each
- Normalization within each reward and then across them as well
In terms of the What, I started with the basics:
- Reward
- Score Delta: I knew that this should be a delta rather than the score itself so I could reward each kill. I did add a normalization factor because the score delta could be 100-500 for regular kills (excluding boss) which was quite high compared to other rewards
- Kill counter: As above, but didn’t need normalization since it was just 1 each
- Floor completion bonus - To egg the agent to complete the floor
- Punish
- Losing Health / Receiving Damage: To tell the agent to avoid losing health. With scaling / Normalization
- Death: The top punisher, to be completely avoided
The idea was reward attacking, and punish getting attacked. Simple enough. And it did achieve some results but not that great.
I was brainstorming reward balancing with Gemini and it gave me this advice which was pivotal:

Agent behavior I observed, as I went through 100s of millions of timesteps of training and kept rebalancing things:
The Kill Farmer: I woke up after a training run and was amazed to see a top high score of around 40000, which is super high. But what I found out amazed me. The agent had learnt, as Gemini predicted, that there is no point in moving around and he could just stand at a place, let the enemies come to him and just keep killing them till the time runs out.
The Risk Averse Family Man: Agent learnt to defend itself well. It was fun to see when 1 or even 2 knifers appeared on the screen and it dodged their thrown knives in perfect tandem for several seconds.
The Chuck Norris: The agent would move towards completing the level but it would be too throw caution to the wind guy, trading blows, losing its own health but being happy with
you should have seen the other guyThe Specialist Who Forgot: Finally, the agent learnt a simple trick to beat the game and optimize for the shortest path to success, even though it had learnt to fight and defend pretty well. Just run. It learnt that the more time you take to move towards the boss, the more enemies the game keeps throwing at you. If you move faster, the less enemies you have to tackle, the more health you have left to fight the boss at the end of the level. You will see in the video at the end of this post, that it ran so fast that it didn’t even let the knife throwers appear at all. What’s even more interesting is that it
forgotto dodge/fight them. Earlier he was pretty good but as he learnt this new trick, he probably determined that his brain cells probably dont need to spend important storage space towards retaining information about the knife throwers at all. So in those late runs, it couldn’t do as well against them when they appeared some times due to timing. You will see this behavior as well if you load the final weights from my code repository to try it out. But if you loaded one from the middle of the training run, it’d be a killing machine against the knife throwers as well.The Glitch Exploiter: He even found a couple of pecularities in the game. He found that if a knifer appears and he hugs the right wall, no new enemies will come from behind him. He also found a glitch that if he just kept running into the boss and pushed him into a corner, the boss will never be able to him. In both these cases, the only thing that made him die was the time out.
The TrickMeister: There’s a mechanic in the game that if you get grabbed by the grabbers, you can’t move until you do a special move of jiggling the direction keys back and forth. Surprisingly, the agent figured that out. And whenever he got grabbed, he does this move to be freed. This can be seen even in the video I’ve linked to at the bottom. It also figured out that the boss always brings down his baton from the top, even if its attacking low, and has a 1-1.5 second of wind up. So the least risky and fastest way to defeat it was to crouch (to delay getting hit by a baton coming down) and give a few quick low kick jabs because of their longer range even though a punch does higher damage.
As a result, I made a ton of changes over 100s of training runs finally settling on:
Scaled down score delta rewards, and scaled up health/death punishment so it is more likely to save its health to actually complete the level and not just kill or defend all the time. I tweaked this a lot and this was a very difficult balance to get right.
Removed kill counter as it didnt provide an additional signal but added some positive noise due to double counting via score.
Added an enemy energy drain reward for multi-hit enemies like knife throwers otherwise when they didn’t die in a single hit, the agent used to think that there’s no point in hitting them since they won’t die anyways, and so if a knife thrower appears he should just throw in the towel.
Added a movement reward: This was very interesting to implement because of the game’s coordinate mechanics I talked about earlier, plus the game throws a few glitches your way by randomly glitching out x/y values often but once i implemented this properly and gave it a reward in proportion to the score delta, and a bit higher for reaching the boss, it made the agent really try to move forward
Added a tiny punishment for wasting time. More the time spent in the middle, the more it would cut points from the agent. This pushed the agent to get a move on, and not wait to get through the things eventually.
Finally I did a lot of tweaks to scale them to appropriate ranges, my aim being that the overall rewards should not become too small or too small (to avoid vanishing or exploding gradients issues).
Link: https://github.com/shantanugoel/kungfu_nes_rl_rust/blob/main/src/env.rs
impl Default for RewardConfig {
fn default() -> Self {
Self {
energy_damage_multiplier: 1.0,
max_valid_score_delta: 5_000,
score_divisor: 100.0,
max_score_reward: 5.0,
reward_scale: 0.1,
hp_damage_multiplier: 0.50,
hp_delta_sanity_bound: -200,
movement_reward_per_pixel: 0.15,
max_movement_delta: 128,
max_valid_movement_delta: 15,
floor_completion_bonus: 20.0,
boss_damage_multiplier: 2.0,
time_penalty: -0.002,
death_penalty: -20.0,
max_energy_drop: 4,
}
}
}
Hyperparameters: The hidden sauce to mastering stability#
DQN can be fragile. Early training runs looked promising, and then collapsed. Q-values explored, policies oscillated, and the agent would forget what it had just learned. The rewards can be noisy because exploration adds randomness. Yet, you can never drop randomness (epsilon) too much because the game randomizes enemy behavior unlike games like Super Mario. So you dont want the agent learning a specific level but expect stochasticity.
There’s no easy way to determine these. There are some typical things that you can take from earlier attempts but ultimately one needs to tweak this for the problem at hand. I had to slow down the learning rate, have a longer warm period before training, a bigger replay buffer, and many more. This makes all the difference between cramming for an exam and spaced repetition, or between getting lucky or truly acing with talent.
I played around with the below parameters, making them more configurable at every turn, and dusting out every single laptop in the house to run parallel training runs.
Link: https://github.com/shantanugoel/kungfu_nes_rl_rust/blob/main/src/dqn.rs
impl Default for AgentConfig {
fn default() -> Self {
Self {
hidden_size: 512,
dueling_hidden_size: 256,
gamma: 0.99,
epsilon_start: 1.0,
epsilon_end: 0.01,
epsilon_decay_steps: 1_000_000,
tau: 0.005,
max_grad_norm: 10.0,
initial_lr: 6.25e-5,
weight_decay: 1e-5,
lr_decay_start: 1_000_000,
lr_decay_factor: 0.5,
total_timesteps: 5_000_000,
replay_capacity: 1_000_000,
batch_size: 256,
learn_start: 20_000,
train_freq: 4,
}
}
}
Confession: The game has moods, and so does the system#
I said all we need for RL is state, action, rewards, right? I lied!
There are a lot of other areas that trip up the learning even though they have nothing to do with the state or actions.
Kung Fu Master spends a lot of time not being playable: Title screens, countdowns, player walking through half of the screen on its own at the start of the screen, death animations, game over, and more. Early on, the agent was collecting transitions in many of these states, which is like expecting a student to learn while the class is on recess, the teacher is nowhere to be found and the whiteboard is empty. I had to create a state machine that became a bit too complex for my taste but it was important to learn only when the game is in real play with the agent being really in control.
Another eureka moment for me was to limit each episode of the training run to each life, instead of the full game of 3 lives.
Finally, I had to overcome the system as well in many ways. Sometimes the runs would crash so I had to add a way to resume. Candle had bugs in memory leaks that lead to usage of 10s of GBs of RAM and swapping to the disk that I had to fix. A bug in the upstream tetanes crate lead me to not be able to use headless mode limiting the perf significantly which I fixed after pouring over the workings of the NES’s 6052 processor for days and pushed a fix upstream (merged now!)
Our boy is finally all grown up!#
Well, it’s all done! The journey to get this running felt like watching your kid learn to stand on his legs and then start running.
After 100+ training runs, billions of timesteps, and countless adjustments to rewards, the agent mastered Floor 1. It speed-runs through the level, exploits game mechanics I didn’t know existed, and beats the boss with ruthless efficiency.
But here’s what I’ll remember most: Every time the agent “misbehaved,” it was actually being totally rational within the constraints I gave it. Kill farming? That’s what I rewarded. Forgetting old skills? That’s efficient resource allocation. Finding shortcuts? That’s problem-solving.
The agent held up a mirror. How many times do we optimize for the wrong metrics? Chase points instead of purpose? Take the path of least resistance when the scenic route teaches more?
Building this taught me that intelligence - artificial or biological - isn’t about having the right capabilities. It’s about having the right incentives.
What would you optimize for if you could redesign your own reward function?
PS: This is ONE of the runs, from one of the many different types of trainings I did. You can play around with the configurations I have done in my code and generate your own playstyle or maybe try to conquer the next floor if you are feeling upto reverse engineering some NES code :D
The full code is available on GitHub